
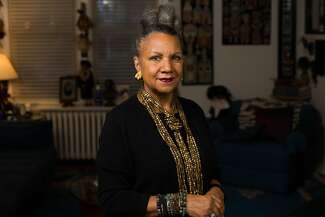


加利福尼亚州参议员霍莉·米切尔站在参议院议会厅,要求她的同事们对黑人的头发进行自我教育,她的金色脏辫松散地盘绕在肩上。
那是2019年4月22日,洛杉矶民主党人正在提出一项立法,将法律保护范围扩大到头发,因为头发对一个人的种族身份至关重要。
“坦率地说,我们谈论的是像我这样的发型,如果不涉及偏见和刻板印象,毫无疑问,这符合职业形象,”米切尔说,他现在是洛杉矶县的一名监督员。

前加州参议员霍莉·米切尔(Holly Mitchell)撰写了《皇冠法案》(CROWN Act),使加州成为第一个禁止在工作场所和公立学校歧视自然头发或发型(如发辫、辫子和麻花辫)的州。
达米安·多瓦加内斯/美联社
sb188法案,即《为自然头发创造一个尊重和开放的世界》(CROWN)法案,很快通过,使加州成为第一个将头发纳入反歧视法的州,特别是自然头发和保护性发型,如脏辫和辫子。
我们将首先审视媒体在使偏见永久化方面所起的作用,这些偏见影响着人们对自己和他人的对待和看法。《纪事报》不会置身事外。在其150年的历史中,它曾发表过一些关于头发的负面种族刻板印象的描述。
《纪事报》分析了美国历史最悠久的时尚杂志《Vogue》20年间的1万多张图片。虽然这本杂志的目的不是反映大多数人的生活经历,但它试图描绘美的顶峰。像许多形式的媒体一样,它告诉人们他们应该想要什么样子。
结果很明显:精灵头、马尾辫和长直发的出现频率远远高于非洲式长发等更宽、更向上的发型。
哪些发型在媒体上最常见(和最少见)?
这是一个简单的问题,但很难回答。
继续滚动阅读更多或直接进入分析.
我们有很多方法可以量化头发在媒体上的表现,从质地到风格。但是为了分析来自数千张图片的数据,我们把重点放在了头发的形状上,它显示了在纹理头发中通常看到的体积在图像中是否被低估了。
我们分析《Vogue》杂志(该杂志的档案可以追溯到1892年)上的照片,主要是因为它允许我们研究2000年以来对头发的现代描绘。为了检测每张图像中的人脸并裁剪它们周围,我们使用了代码。上面的脸是从同一页上剪下来的。
这张图片实际上可以告诉你很多关于媒体表现的信息。这是我们分析的所有《Vogue》图片的“平均”表现——像素越白,在那个位置有头发的图片就越多。我们看到的是,很多照片的顶部都有毛发;而那些头发较多的人倾向于留长发,而不是宽大或蓬松的发型。
我们的分析表明,在大多数图像中,头发在画面中所占的比例很小。换句话说,《Vogue》很少描绘长头发.这些图像中的大多数都带有更少的头发相框里是小精灵般的发型,长发扎成马尾。



超过1/3的图像由前三个条表示



29张照片中至少有40%是头发。他们的条形图在图表中几乎看不出来。
除了看照片中头发的数量,我们还会寻找照片中头发最多的地方。头发的平均位置在头顶附近吗?双方?这可以告诉我们更多关于《Vogue》照片中所代表的头发类型。
我们发现,当图像中有更多的头发时,头发倾向于在图像的底部。所以当头发比a多的时候pixie削减,那头发更有可能是长,而不是宽的或垂直的,这是我们期望的图像大量的还有有质感的头发。
触摸这些点可以看到图像。
虽然种族(或任何种族的粗略近似)不包括在分析中,但我们的研究结果表明,自然的黑色发型远不如其他发型具有代表性。
这种分析只是更好地理解媒体多样性的一步。我们邀请您阅读更多关于我们的方法,并通过点击下面的按钮将您自己的图像上传到模型。
所有关于人类经验的研究都应该以英寸为单位,而不是以英里为单位,因为数据和资源总是有局限性的。例如,我们的分析仅限于头发大小,没有包括发型或质地。我们认为这一分析的警告是进一步探索的邀请。
在以后的章节中,我们将涵盖头发:欢乐,艰辛和两者之间的一切。我们将听到企业家、教育工作者、政策制定者和人们对头发的看法。特别是,我们将询问人们如何才能使我们的世界成为一个没有人会觉得自己的头发不合适的世界。
方法
我们从一个基本的问题开始:哪种发型在媒体上最受关注(和最不受关注)?这是一个简单的定量问题,但却充满了障碍。什么数据集可以回答这个问题?数据是否可访问且具有代表性?我们应该尝试测量什么?最终,我们关心的是什么是可行的,以及我们可以在不引入偏见的情况下从数据集中排除什么。我们没有对图像中所代表的种族或性别进行任何分析,但这两者都值得进一步研究。
的数据
在我们的这组图片中,我们将自己的范围限制在2000年至最近的《Vogue》档案(在分析时,是2021年4月的那期,赛琳娜·戈麦斯(Selena Gomez)穿着一件漂亮的露肩花裙,里面衬着黑色皮毛)。当然,《Vogue》并不能代表所有媒体。但它是世界上最多产的时尚和美容出版物之一。它有一个档案,大多数人都可以通过互联网连接和图书馆卡访问。我们手动下载了《Vogue》数据库中所有包含照片的内容。
这里有一些限制:首先,我们没有捕捉到很多理解表现的关键内容,比如广告。我们的工作仅限于封面、时装摄影和文章。其次,由于我们下载数据的网站ProQuest的限制,我们只拉出每篇列出的文章的第一页或双页传播。例如,对于一篇六页的文章,我们最多只能从前三分之一的内容中抓取图像。
一旦我们将所有数据下载到pdf中,我们就使用人脸检测(与人脸识别不同!)在每个页面上找到人脸,然后裁剪人脸周围的图像,并将图像写入PNG文件。
杂志整页和封面之前的文字通常包含出版日期,但并非总是如此。我们曾希望对代表性如何随时间变化进行更深入的分析,但由于列出的大部分内容没有发布日期,因此无法进行深入分析。
我们从分析中排除了那些在检测到的人脸周围裁剪的图像,这些图像的分辨率不足以让我们的机器学习模型接受。我们还手动丢弃了任何未正确检测到人脸的图像。有许多明显重复的图像,我们没有丢弃,因为它们通常表示共享文章页面的内容的交叉列表,但它们有时也会出现不止一次,因为图像被重新发布。最后,我们有超过11000张图片需要分析。
该模型
除了编译数据集,我们还必须训练机器学习模型来识别图像中的头发——这个过程被称为“分割”。更具体地说,模型接受图像并返回给定像素是头发的可能性的灰度表示-在下面的模型输出图像中(在机器学习中通常称为“标签”或“掩模”),像素越轻,模型越确定图像对应坐标中的像素是头发,反之亦然。

下一节将涉及更多的技术,所以请系好安全带。如果你以前没有接触过机器学习,下面的一些术语可能对你来说不熟悉。
我们训练模型Figaro1K该数据集包含1050张图像,这些图像是意大利布雷西亚大学的研究人员手动“标记”的(这意味着他们浏览了每张图像,并创建了看起来很像我们一直在看的黑白图像的蒙版)。一旦模型进行了初始训练,我们处理自己的数据并手工选择最佳输出来重新训练原始的U-NET模型,以及我们手动标记的一些图像。
在经历了一段陡峭的学习曲线之后,本文中用于分析的最终模型是在1501张图像上进行训练的。这种模式并不完美。它与低照明和分辨率,以及纹理和一些头饰作斗争。
一旦最终模型处理了数据集,我们使用一个称为“阈值”的过程将灰度图像转换为二值标签——基本上,如果模型至少有50%的把握像素是头发,我们将像素转换为白色;少于这个数,我们就把它涂黑。然后我们梳理面具,将它们与图像进行比较,并丢弃任何识别出的头发明显来自图像中另一个人的数据,或者如果模型在很大程度上是错的(即,要么许多白色像素明显不是图像中的头发,要么许多黑色像素明显是图像中的头发)。这个过程是一个可能引入错误的判断。
分析
然后我们测量了从图像中提取的数据。首先,我们计算了每张图像中由头发组成的百分比——这是一种测量大头发出现频率的简单方法。
我们还想更好地理解这些头发像素在图像中的分布,所以我们计算了头发形状的质心(图像中代表平均x值和平均y值的点)。我们还添加了一个边界框,其中至少98个像素(每张图像中平均头发像素数的1%)被捕获在线外。这可以防止盒子将一些错误的像素解释为头发的最外层边缘。即使当模型不正确地对图像区域进行分类时,边界框通常对这些错误具有鲁棒性,并返回有意义的准确结果。

